
VGG-Flow团队 投稿开云体育(中国)官方网站
量子位 | 公众号 QbitAI
用强化学习微调扩散模子,还有更好的办法吗?
来自港中深、微软辩论院等机构的VGG-Flow团队给出了一个新想路:既然奖励函数自己是可微的,为什么非要绕弯路用PPO、GRPO。

在大范围生成模子的对都任务中,通常依赖强化学习,在某个奖励函数上微调模子以迫临东说念主类偏好。而事实上,大部分奖励模子自己是在偏好数据集上磨练过的神经荟萃。既然奖励是可微的,能否胜利欺诈“可微性”自己,高效而安详地微调流匹配模子?
主流作念法主要分为两类旅途:一条路是把模子算作黑盒,通过像Flow-GRPO那样,把蓝本确定性的ODE采样进程强行转为随即SDE,适配经典的强化学习框架来遴荐高方差的计谋梯度神色(如PPO、GRPO)。
另一条路则愈加胜利,如ReFL等神色,通过相似技艺优化某些取样步对应的奖励值,但这种作念法在看法层面上穷乏严格的表面相沿,也往往容易导致过拟合与形态崩塌。那么是否不错走一条新蹊径?
VGG-Flow团队记忆第一性旨趣,将奖励微调再行表述为一个连合时辰最优戒指问题。通过Hamilton–Jacobi–Bellman(HJB)方程,胜利将“可微奖励”移动为价值梯度,为流匹配对都提供了一条更安详、更鲁棒的旅途。现在该技俩已被NeurIPS 2025罗致。
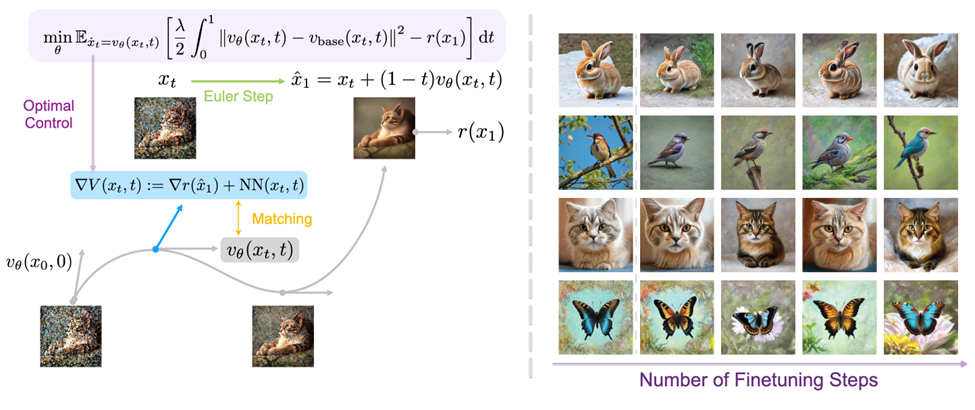
VGG-Flow的中枢想路:最大化“终态奖励−累计代价”
流匹配模子通过在随即取样的x₀上模拟时辰t=0到t=1的轨迹ẋ=v(x,t)来生成样本,其中v(x,t)是流匹配模子的速率场。
微调后的速率场不错被写成预磨练模子与残差的和:vθ(x,t)=vbase(x,t)+ṽθ(x,t),其中预磨练模子是vbase(x,t),残差是ṽθ(x,t)。
直不雅来看,为了幸免模子在微调进程中过度偏离原有散播,微调在最大化样本奖励的同期,需要治理预磨练模子与微调模子在取样旅途上的差:
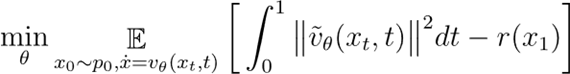
从最优戒指的角度看,这即是一个终态看法加上一段旅途累计代价(cost-to-go)。
HJB方程:从价值到梯度的融会直观
在最优戒指表面中,价值函数V(x,t)态状了从现象(x,t)开拔的最优预期老本。凭据界说,上述看法对应如下的价值函数:
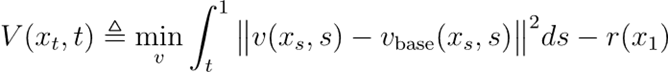
其演化知足以下Hamilton–Jacobi–Bellman(HJB)方程(强化学习中贝尔曼方程的连合时辰体式):
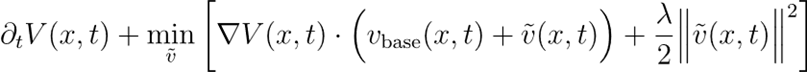
由此不错赢得最优修正项的融会体式:
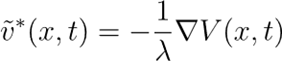
这赢得一个相当胜利的论断:最优微调场地=价值函数的梯度。
不需要采样上风函数,不需要猜度打算对数概率比,也不需要进行计谋比值剪辑。只需猜度价值梯度,即可胜利、可微地更新流匹配模子。
这个价值函数奈何赢得?将最优速率场代回HJB方程,不错赢得如下的价值一致性策动:
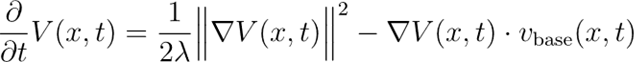
通过求解知足该一致性策动的价值函数,即可赢得用于磨练速率场的看法梯度。
参数化:将先验写入梯度
为了使价值梯度∇V(x,t)在磨练初期具备合理的涵养场地,VGG-Flow引入了Forward-looking参数化神色:
1. 预估特殊:在xt处进行一步Euler前推,赢得预估特殊
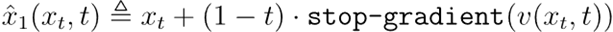
2. 参数化涵养:欺诈一步前推的奖励梯度对价值梯度∇V(x,t)进行参数化:
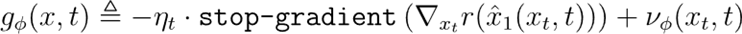
其中ηt为随时辰减小而减小的标量权重,
为可学习的残差项。
在这种想象下,模子仅需学习残差项即可杀青对都。团队在实验中发现,即使不学习残差,仅依赖奖励梯度的参数化涵养也能杀青显着的对都后果。这一技巧不错权臣裁汰流匹配模子微调的猜度打算老本。
优化看法:在该框架下,VGG-Flow的亏欠函数不错写为:
1. 梯度匹配亏欠:使速率场修正项拟合价值梯度
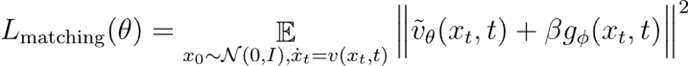
2. 价值一致性亏欠:最小化HJB方程的残差
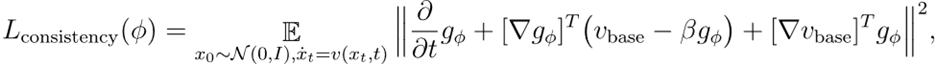
3. 结尾范围亏欠:凭据价值函数界说,确保t=1时的范围条目建造
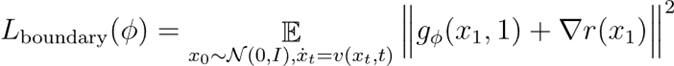
注:若遴荐上一节所述的成立(即不学习价值梯度中的残差项
),仅需优化梯度匹配亏欠。
实验后果
在Stable Diffusion 3上的实验中,仅需400次更新,VGG-Flow即可杀青奖励信号的安详进步。在Aesthetic和PickScore方针上,神色展现出较高的拘谨遵守与精致的各样性保捏智商。比较ReFL、DRaFT等神色,其发挥更为谨慎,更不易淡忘预磨练模子中的先验,生成结果愈加当然。其拘谨也快,何况胜利作用于流匹配模子自己,无需罕见将ODE调度为SDE。

△ 图1:Stable Diffusion 3在Aesthetic Score奖励下遴荐VGG-Flow微调的结果

△ 图2:Stable Diffusion 3在PickScore奖励下遴荐VGG-Flow微调的结果
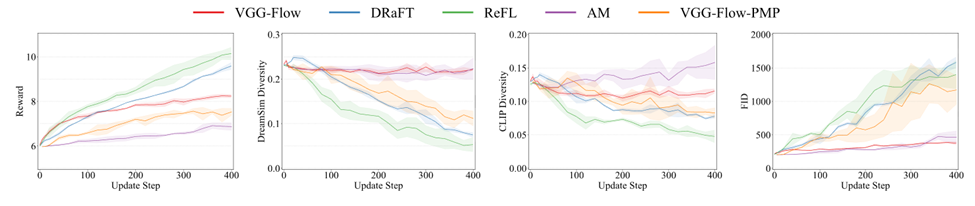
△ 图3:在Aesthetic Score奖励下,奖励值、各样性方针与FID的拘谨弧线。其中,奖励值、DreamSim各样性与CLIP各样性越高越好;FID越低越好。
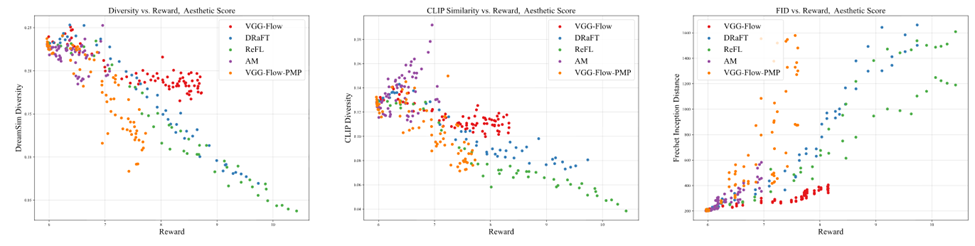
△ 图4:不同微调神色在各项方针上的帕累托前沿。每个点示意某次磨练进程中保存的某个checkpoint(共使用3个不同随即种子)。
总结
本文建议VGG-Flow,在连合时辰最优戒指框架下,学习空间中每少量的价值函数梯度,并使速率场向其对都,从而杀青结构一致的可微奖励微调。
由于优化看法是匹配局部梯度,而非胜利最大化终态奖励,该神色在实践中发挥出更好的安详性与鲁棒性。实验结果露馅,VGG-Flow在现存文生图模子上大致快速拘谨,同期保捏生成质地与各样性,为基于可微奖励函数的高效微调提供了一种新的想路。
此辩论已收录于NeurIPS 2025
论文地址:
https://arxiv.org/abs/2512.05116
技俩网站:
https://vggflow25.github.io
开源代码:
https://github.com/lzzcd001/vggflow
一键三连「点赞」「转发」「防备心」
宽容在批驳区留住你的想法!
— 完 —
咱们正在招聘又名眼疾手快、温和AI的学术编著实习生 🎓
感兴趣兴趣的小伙伴宽容温和 👉 了解笃定

🌟 点亮星标 🌟
科技前沿进展逐日见开云体育(中国)官方网站